微服务篇
微服务面试相关问题整理
什么是单体架构?
将业务的所有功能集中在一个项目中开发,打成一个包部署。
单体架构的优缺点如下:
优点:
- 架构简单
- 部署成本低
缺点:
- 耦合度高(维护困难、升级困难)
什么是分布式架构?
分布式架构就是根据业务功能做拆分,每个业务功能模块作为独立项目开发,称为一个服务,将不同的业务提取出来部署在不同的服务器上。
① 分布式架构的出现是为了用廉价的,普通的及其完成单个计算机无法完成的计算,存储任务, 其目的就是利用更多的机器,处理更多的数据。
② 单个服务器无法承受大量的服务,对于大量的用户进行访问是无法处理这种流量,此时就需要利用 更多的机器来分担这种流量访问的压力,因此此时就利用到了"分布式架构"将 每一个不同的服务部 署在不同机器上,来处理不同的请求,缓解单个服务器被访问压力。
③ 只有单个节点的处理能力无法满足需求(内存+磁盘+cpu),才需要用到分布式,因为分布式系统要解决 的问题本身适合单机系统一样的,但是由于分布式系统多节点,在网络通信中,会出现很多单机系统没有的问题。
- 将一个大的系统划分为多个业务模块,业务模块分别部署到不同的机器上,各个业务模块之间通过接口进行数据交互。 区别分布式的方式是根据不同机器不同业务。
分布式架构的优缺点:
优点:
- 降低服务耦合
- 有利于服务升级和拓展
缺点:
- 服务调用关系错综复杂
分布式架构虽然降低了服务耦合,但是服务拆分时也有很多问题需要思考:
- 服务拆分的粒度如何界定?
- 服务之间如何调用?
- 服务的调用关系如何管理?
人们需要制定一套行之有效的标准来约束分布式架构。
微服务架构特点是什么?
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务, 服务之间互相协调,互相配合,为用户提供最终价值。
特点:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责
- 自治:团队独立、技术独立、数据独立,独立部署和交付
- 面向服务:服务提供统一标准的接口,与语言和技术无关
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
微服务的上述特性其实是在给分布式架构制定一个标准,进一步降低服务之间的耦合度,提供服务的独立性和灵活性。做到高内聚,低耦合。
因此,可以认为微服务是一种经过良好架构设计的分布式架构方案 。
服务怎么拆分?
选择合适的拆分粒度:一般基于业务功能进行拆分。
微服务拆分时的几个原则:
- 单一职责:不同微服务,不要重复开发相同业务
- 数据独立:微服务数据独立,不要访问其它微服务的数据库
- 面向服务:微服务可以将自己的业务暴露为接口,供其它微服务调用
SpringCloud 常见组件有哪些?
问题说明:这个题目主要考察对 SpringCloud 的组件基本了解
难易程度:简单
参考话术:
SpringCloud 包含的组件很多,有很多功能是重复的。其中最常用组件包括:
•注册中心组件:Eureka、Nacos 等
•负载均衡组件:Ribbon
•远程调用组件:OpenFeign
•网关组件:Zuul、Gateway
•服务保护组件:Hystrix、Sentinel
•服务配置管理组件:SpringCloudConfig、Nacos
服务间是怎么远程调用的?
RestTemplate 到 Open Feign,只需要知道服务 ID 和接口路径就可以调用服务。
这里要引入服务的注册中心了,可以使用 Eureka 或 Nacos,见 问题 1.5.Nacos 与 Eureka 的区别有哪些?
调用时结合负载均衡组件,发起远程调用时会被 LoadBalancerInterceptor 拦截,从注册中心拉取服务列表,根据负载均衡算法得到真实的服务地址信息,替换服务 ID,请求到服务对应实例。
相关负载均衡算法:轮询、权重、Zone 机房轮询、随机、选择并发低的服务器等等。
Nacos 的健康检测有两种模式
- ==临时实例==:
- 采用客户端心跳检测模式,心跳周期 5 秒
- 心跳间隔超过 15 秒则标记为不健康
- 心跳间隔超过 30 秒则从服务列表删除
- ==永久实例==:
- 采用服务端主动健康检测方式
- 周期为 2000 + 5000 毫秒内的随机数
- 检测异常只会标记为不健康,不会删除
Nacos 的服务发现分为两种模式
- 模式一:==主动拉取模式==,消费者定期主动从 Nacos 拉取服务列表并缓存起来,再服务调用时优先读取本地缓存中的服务列表。
- 模式二:==订阅模式==,消费者订阅 Nacos 中的服务列表,并基于 UDP 协议来接收服务变更通知。当 Nacos 中的服务列表更新时,会发送 UDP 广播给所有订阅者。
与 Eureka 相比,Nacos 的订阅模式服务状态更新更及时,消费者更容易及时发现服务列表的变化,剔除故障服务。
那么为什么 Nacos 有临时和永久两种实例呢?
以淘宝为例,双十一大促期间,流量会比平常高出很多,此时服务肯定需要增加更多实例来应对高并发,而这些实例在双十一之后就无需继续使用了,采用临时实例比较合适。而对于服务的一些常备实例,则使用永久实例更合适。
Nacos 与 Eureka 的区别有哪些?
参考话术:
Nacos 与 Eureka 有相同点,也有不同之处,可以从以下几点来描述:
- 接口方式:Nacos 与 Eureka 都对外暴露了 Rest 风格的 API 接口,用来实现服务注册、发现等功能
- 实例类型:Nacos 的实例有永久和临时实例之分;而 Eureka 只支持临时实例
- 健康检测:Nacos 对临时实例采用心跳模式检测,对永久实例采用主动请求来检测,eureka 是==30==秒,Nacos 是==5==秒;Eureka 只支持心跳模式
- 服务发现:Nacos 支持定时拉取和订阅推送两种模式;Eureka 只支持定时拉取模式
另外,nacos 还支持做服务的配置中心。
Nacos 的服务注册表结构是怎样的?
Nacos 采用了数据的分级存储模型,最外层是 Namespace,用来隔离环境。然后是 Group,用来对服务分组。接下来就是服务(Service)了,一个服务包含多个实例,但是可能处于不同机房,因此 Service 下有多个集群(Cluster),Cluster 下是不同的实例(Instance)。
对应到 Java 代码中,Nacos 采用了一个多层的 Map 来表示。结构为 Map<String, Map<String, Service>>,其中最外层 Map 的 key 就是 namespaceId,值是一个 Map。内层 Map 的 key 是 group 拼接 serviceName,值是 Service 对象。Service 对象内部又是一个 Map,key 是集群名称,值是 Cluster 对象。而 Cluster 对象内部维护了 Instance 的集合。
Nacos 如何支撑阿里内部数十万服务注册压力?
Nacos 内部接收到注册的请求时,不会立即写数据,而是将服务注册的任务放入一个阻塞队列就立即响应给客户端。然后利用线程池读取阻塞队列中的任务,异步来完成实例更新,从而提高并发写能力。
Nacos 如何保证并发写的安全性?
首先,在注册实例时,会对 service 加锁,不同 service 之间本身就不存在并发写问题,互不影响。相同 service 时通过锁来互斥。并且,在更新实例列表时,是基于异步的线程池来完成,而线程池的线程数量为 1.
Nacos 如何避免并发读写冲突问题?
Nacos 在更新实例列表时,会采用 CopyOnWrite 写时复制技术,首先将旧的实例列表拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表来覆盖旧的实例列表。
这样在更新的过程中,就不会对读实例列表的请求产生影响,也不会出现脏读问题了。
分布式事务 Seata
Seata 事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
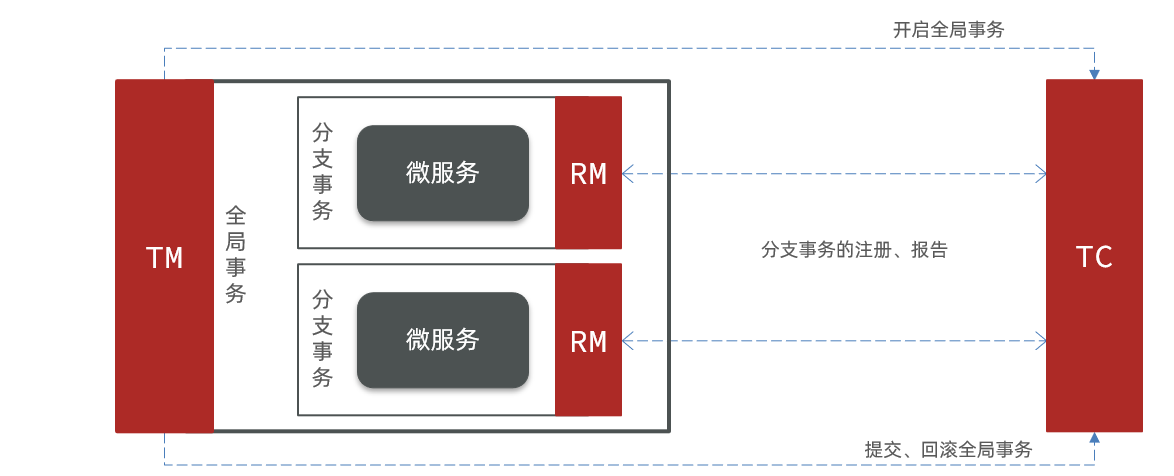
Seata 基于上述架构提供了四种不同的分布式事务解决方案:
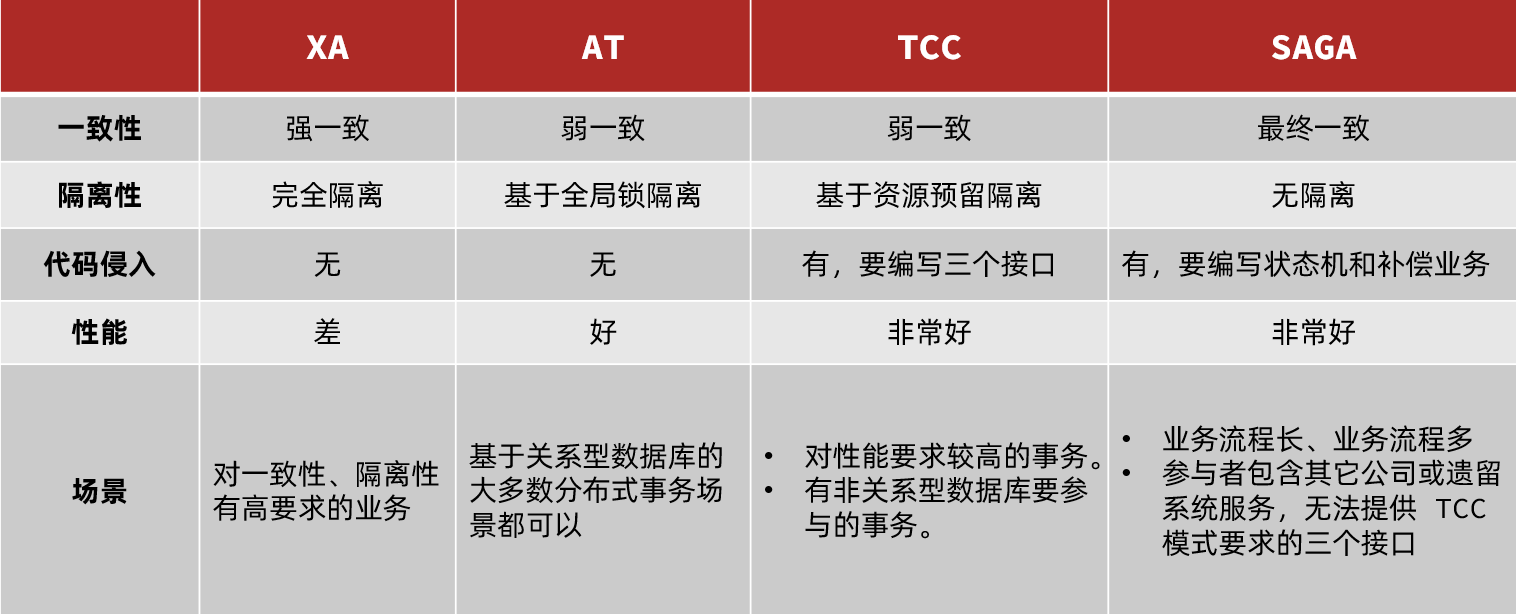
- XA 模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- AT 模式:最终一致的分阶段事务模式,无业务侵入,也是 Seata 的默认模式
- TCC 模式:最终一致的分阶段事务模式,有业务侵入
- SAGA 模式:长事务模式,有业务侵入
无论哪种方案,都离不开 TC,也就是事务的协调者。
XA 模式
两阶段提交:
- 一阶段:事务协调组通知每个事务参与者执行本地事务,本地事务执行完成后报告事务执行状态给事务协调者,此时事务是不提交的,继续持有数据库锁
- 二阶段:如果一阶段都成功,通知所有事务参与者提交事务;否则,通知所有事务参与者回滚
优点:
- 事务强一致性,满足 ACID 原则。
- 常用数据库都支持,实现简单,没有代码侵入。
缺点:
- 性能差,阶段一锁定资源,阶段二才释放
- 依赖关系型数据库实现事务
AT 模式
AT 模式同样是分阶段提交的事务模型,不过缺弥补了 XA 模型中资源锁定周期过长的缺陷。
两阶段提交:
- 一阶段:类似 XA 模式,但是执行事务前会先对数据库做一个快照 undo-log,然后分支事务直接执行并提交。
- 二阶段:如果一阶段都成功,删除 undo log;否则,根据 undo log 回滚数据
AT 模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能比较好
- 利用全局锁实现读写隔离
- 没有代码侵入,框架自动完成回滚和提交
AT 模式的缺点:
- 两阶段之间属于软状态,属于最终一致
- 框架的快照功能会影响性能,但比 XA 模式要好很多
简述 AT 模式与 XA 模式最大的区别是什么?
- XA 模式一阶段不提交事务,锁定资源;AT 模式一阶段直接提交,不锁定资源。
- XA 模式依赖 数据库机制 实现回滚;AT 模式利用 数据快照 实现数据回滚。
- XA 模式强一致;AT 模式最终一致。
TCC 模式
TCC 模式与 AT 模式非常相似,每阶段都是独立事务,不同的是 TCC 通过人工编码来实现数据恢复。需要实现三个方法:
Try:资源的检测和预留;
Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
Cancel:预留资源释放,可以理解为 try 的反向操作。
TCC 模式的每个阶段是做什么的?
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源的释放
TCC 的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比 AT 模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC 的缺点是什么?
- 有代码侵入,需要人为编写 try、Confirm 和 Cancel 接口,太麻烦
- 软状态,事务是最终一致
- 需要考虑 Confirm 和 Cancel 的失败情况,做好幂等处理
SAGA 模式
在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
Saga 也分为两个阶段:
- 一阶段:直接提交本地事务
- 二阶段:成功则什么都不做;失败则通过编写补偿业务来回滚
优点:
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写 TCC 中的三个阶段,实现简单
缺点:
- 软状态持续时间不确定,时效性差
- 没有锁,没有事务隔离,会有脏写
四种模式对比
微服务保护 Sentinel
簇点链路:当请求进入微服务时,首先会访问 DispatcherServlet,然后进入 Controller、Service、Mapper,这样一个调用链就叫做簇点链路。簇点链路中被监控的每一个接口就是一个资源。
四大功能:流量控制、隔离和降级、热点参数、授权规则。
- 流控:流量控制
- 降级:降级熔断
- 热点:热点参数限流,是限流的一种
- 授权:请求的权限控制
流量控制
流控模式:==直接==、==关联== 和 ==链路==。
- 直接:统计当前资源的请求,触发阈值时对当前资源限流。默认。
- 关联:统计与当前资源相关联的另一个资源的请求,触发阈值时对当前资源限流。
- 场景:修改和查询订单,会导致争抢数据库锁。业务需求是优先更新订单,因此更新订单触发阈值时,对查询订单业务限流。
- 链路:统计从指定链路访问到当前资源的请求,触发阈值时对指定链路限流。
流控效果:==快速失败==、==warm up== 和 ==排队等待==。
- 快速失败:到达阈值后,新的请求会被立即拒绝并抛出 FlowException 异常。默认。
- warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常,但这种模式阈值会动态变化,从一个较小值逐渐增加到最大值。
- 排队等待:让所有请求按照先后次序排队进行,两个请求的间隔不能小于指定时长。
热点参数限流:分别统计 参数值 相同的请求,判断是否超过阈值。
隔离和降级
都是通过调用方发起远程调用来实现的,所以需要配合 Feign 来实现。编写失败降级逻辑:实现 FallbackFactory 接口,重写对应 FeignClient 的方法。
线程隔离(舱壁模式),调用者在调用服务提供者时,给每个调用的请求分配独立的线程池,出现故障时,最多消耗这个线程池内的资源,避免把调用者的所有资源耗尽。
限流时选择阈值类型为线程数,是采用线程数隔离,信号量隔离(Sentinel 默认采用),计数器模式记录业务的线程数量。
熔断降级:是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。
断路器熔断策略有三种:==慢调用==、==异常比例==、==异常数==。
- 慢调用:RT 大于指定时长的请求就是一次慢调用请求。在指定时间内,大于设定的阈值,触发熔断。
- 异常比例和异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
授权规则
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。配合网关做授权。
规则持久化
- 原始模式:保存在内存
- pull 模式:客户端的内存和本地文件存储规则
- push 模式:规则推送到配置中心,客户端监听 nacos 配置变更,完成本地配置更新
Sntinel 的限流与 Gateway 的限流有什么差别?
限流算法常见的有三种实现:滑动时间窗口、令牌桶算法、漏桶算法。
Gateway 则采用了基于 Redis 实现的令牌桶算法。
而 Sentinel 内部却比较复杂:
- 默认限流模式是基于滑动时间窗口算法
- 排队等待的限流模式则基于漏桶算法
- 而热点参数限流则是基于令牌桶算法
Sentinel 的线程隔离与 Hystix 的线程隔离有什么差别?
问题说明:考察对线程隔离方案的掌握情况
难易程度:一般
参考话术:
Hystix 默认是基于线程池实现的线程隔离,每一个被隔离的业务都要创建一个独立的线程池,线程过多会带来额外的 CPU 开销,性能一般,但是隔离性更强。
Sentinel 是基于信号量(计数器)实现的线程隔离,不用创建线程池,性能较好,但是隔离性一般。