JVM 篇
1.JVM 内存结构
记住这个图
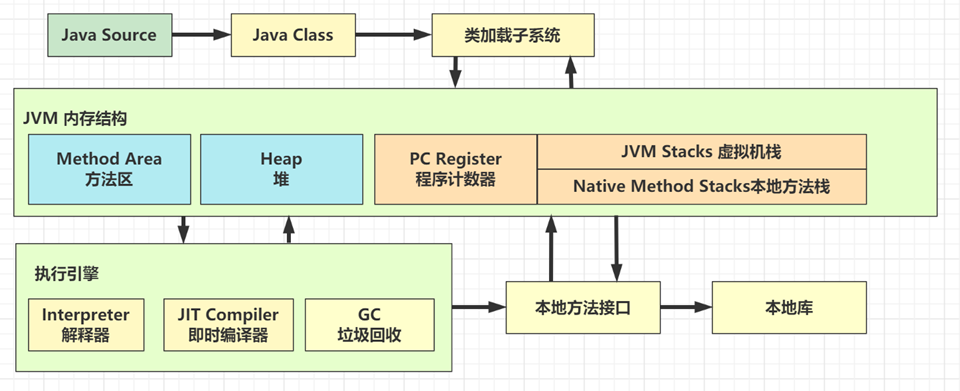
运行时数据区:方法区、堆、虚拟机栈、本地方法栈、程序计数器。
方法区:类的元数据、即时编译器的代码缓存。
堆:用来存放对象实例。JDK7 把字符串常量池、静态变量放到了堆中。
虚拟机栈:每个方法执行时都会创建一个栈帧,存放局部变量表、操作数栈、动态连接、方法出口等信息。
本地方法栈:和虚拟机栈类似,主要是 Native 方法存储相关信息。Oracle 的 Hotspot 虚拟机是合二为一的。
程序计数器:用来记录当前线程下一条 JVM 字节码指令的执行地址。如果是本地方法计数器为空。
- 堆和方法区是线程共享的。
- 虚拟机栈、本地方法栈、程序计数器是线程私有的。
内存溢出的区域
程序计数器不会内存溢出。
OutOfMemoryError:
- 堆内存耗尽:对象越来越多,一直使用不能回收。
- 方法区内存耗尽:加载的类越来越多,动态生成大量类。
- 虚拟机栈耗尽:每个线程最多占用 1M 内存,线程个数越来越多,又不销毁。
StackOverflowError:
- JVM 虚拟机栈:==方法递归==调用没有正确结束,反序列化 JSON 时==循环引用==。
OOM 内存溢出问题
说出几种典型的内存溢出情况
- ==堆内存==:线程池使用无界阻塞队列 LinkedBlockingQueue,任务堆满了,堆内存溢出。
- ==堆内存==:查询数据量太大。
- ==虚拟机栈==:线程池使用 newCachedThreadPool,线程创建数量大,超过了虚拟机允许最大栈内存。
- ==方法区==:反射动态生成类。
方法区、永久代、元空间之间的关系
- 方法区:JVM 规范定义的一块内存区域,用来存储类元数据、方法字节码、即时编译器需要的信息。
- 永久代:1.8 前 Hotspot 虚拟机对 JVM 规范的实现
- 元空间:1.8 后 Hotspot 虚拟机对 JVM 规范的实现,使用本地内存作为这些信息的存储空间。
常见的 JVM 内存参数
-Xms:最小堆内存
-Xmx:最大堆内存
建议设置成大小相等,不需要保留内存来动态扩大和缩小,这样性能好。
-XX:NewSize 与 -XX:NewSize 设置新生代的最小值和最大值,建议不要设置,JVM 自己控制。
-Xmn:设置新生代大小,相当于同时设置了-XX:NewSize 与 -XX:NewSize,并且取值相等。
-XX:SurvivorRatio:幸存区比例
垃圾回收算法
三种算法:标记清除、标记整理、标记复制
1. 标记清除法
过程:
找到 GC Root 对象(GC Root 对象:一定不会被回收的对象,局部变量和静态变量引用的对象)
标记阶段:沿着 GC Root 对象的引用链找,直接或间接引用到的对象加上标记
清除阶段:直接释放未加标记对象占用的内存
优点:速度较快
缺点:会产内存碎片,造成空间不连续
要点:
- 标记速度和存活对象成线性关系
- 清除速度和对象大小成线性关系
2. 标记整理法
过程:
标记阶段、清除阶段和标记清除法类似
整理阶段:将存活对象朝着一段移动,避免内存碎片产生
优点:没有内存碎片
缺点:速度比标记清除慢
要点:
- 标记速度和存活对象成线性关系
- 清除与整理速度和对象大小成线性关系
3. 标记复制法
过程:
- 将整个内存分为两块大小相等的区域,from 和 to,其中 to 总是处于空闲,from 存储新创建的对象
- 标记阶段和前面算法类型
- 找出存活对象后,会把他们从 from 复制到 to 区域,复制过程中自然完成了碎片整理
- 复制完成后,交换 from 和 to 的位置
特点:
- 标记与复制速度与存活对象成线性关系
优点:没有内存碎片,比标记整理速度快
缺点:占用双倍内存空间
3.GC 和分代回收算法
GC:就是垃圾回收,实现对无用对象内存自动释放,减少内存碎片、加快分配速度。
回收区域:堆内存,不用回收虚拟机栈,虚拟机栈内存随着线程的销毁而释放
可以作为 GC Roots 的对象:
- 虚拟机栈栈帧的本地变量表引用的对象
- 方法区静态变量引用的对象
- 方法区常量引用的对象
- 本地方法栈中 JNI(Native 方法)引用的对象
- 虚拟机内部的引用,Class 类、异常类、类加载器
- synchronized 关键字修饰的对象
判断无用对象:可达性分析算法、三色标记法,标记存活对象,回收未标记对象
- 三色标记:黑色已标记,灰色标记中,白色还未标记
分代回收思想:
大部分对象都是朝生夕灭的,用完立刻就可以回收。熬过越多次垃圾回收的对象就越难以消亡。
根据这个特性,将回收区域分为老年代和新生代,新生代一般采用标记复制算法,老年代一般采用标记整理算法。
新生代:伊甸园 eden、幸存区 survivor(分为 from 和 to)
老年代:幸存区对象熬过最多 15 次垃圾回收,晋升到老年代。(幸存区内存不足或者大对象会导致提前晋升)
GC 规模:Minor GC,Mixed GC,Full GC
- Minor GC:发生在新生代,暂停时间短
- Mixed GC:发生在新生代和老年代,G1 收集器特有的
- Full GC:发生在新生代和老年代完整垃圾回收,暂停时间长,尽力避免
4. 垃圾回收器
1. Serial 串行
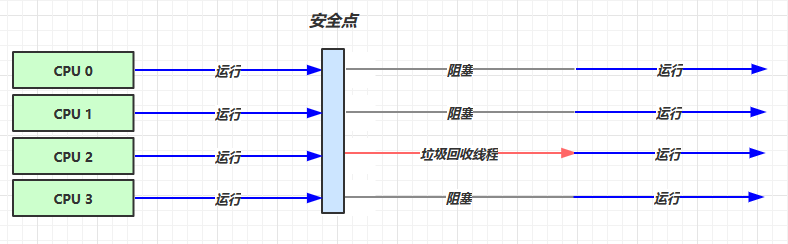
2. Parallel 吞吐量优先
Serial 收集器的多线程版本
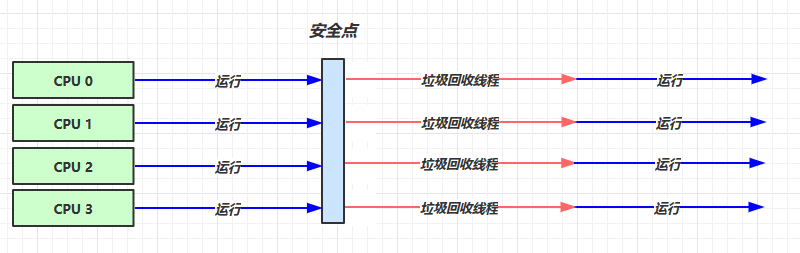
3. CMS 响应时间优先
初始标记、并发标记、重新标记、并发清理
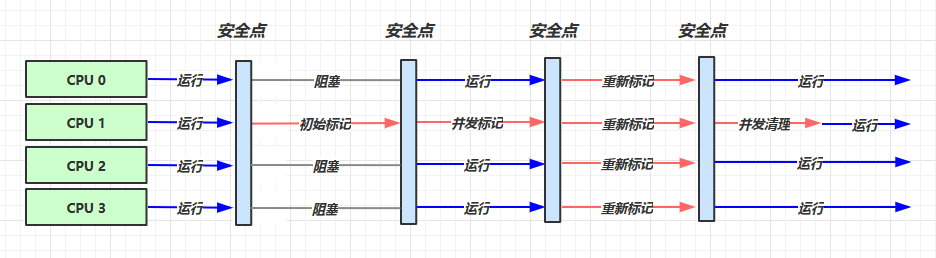
重新标记会根据卡表再次遍历
并发清理可能产生浮动垃圾,可能导致并发失败,采用 Serial Old 收集器
4. G1 吞吐量 + 低延迟 JDK 9 默认
G1 垃圾回收器:注重吞吐量和低延时(默认 200ms),会把堆划分成多个大小相等的 Region,2048 左右个,每个在 1~32MB 之间。
分代:每个 Region 代表一个类型,young、old。
- young:eden、survivor
- old:old、Humongous(超过 region 的一半时)
整体上是标记整理算法,两个区域之间是复制算法
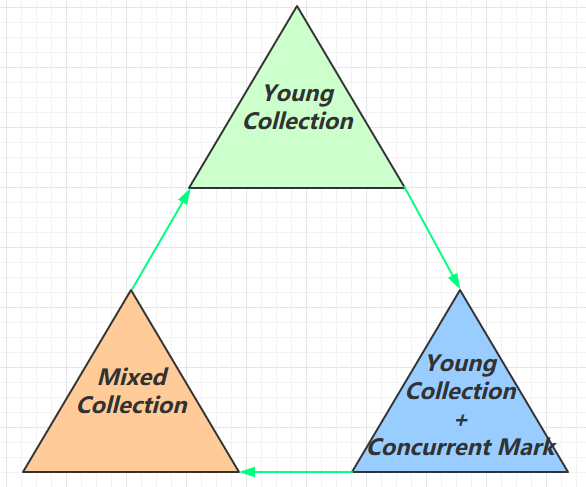
回收阶段:
- Young Collection:会 STW,初始标记。
- Young Collection + Concurrent Mrak :老年代堆空间比例达到阈值时,并发标记,不会 STW
- Mixed Collection:会对 Eden、Survivor、Old 进行全面的垃圾回收
- 最终标记 会 STW
- 拷贝存活 会 STW
多标问题:产生浮动垃圾。
并发标记时漏标问题:
==增量更新法(Incremental Update)==,CMS 垃圾回收器采用,写屏障 + 增量更新
- 每次拦截赋值动作,只要赋值发生,被赋值的对象就会被记录下来,在重新标记阶段再确认一遍。
==原始快照法(SATB,Snapshot At The Beginning)==,G1 垃圾回收器采用,写屏障 + 原始快照
- 每次拦截赋值动作,不过记录的对象不同,也需要在重新标记阶段对这些对象二次处理
- 新加对象会被记录
- 被删除的引用关系的对象也被记录
跨代引用问题
老年代引用新生代,新生代回收时遍历的问题
方法:每个 Region 都维护了一个记忆集卡表,一旦一个老年代对象引用了新生代对象时,都标记为脏 card。
每次对象引用变更时通过一个写后屏障来维护。
类加载过程
加载将类的字节码载入方法区,并创建类的 class 对象
如果这个类的父类没有加载,先加载父类
加载是懒惰执行的,用到了才加载
链接- ==验证==:验证是否符合 Class 规范,合法性、安全性检查
- ==准备==:为 static 变量分配空间,设置默认值,static final 修饰的基本类型变量赋值
- ==解析==:将常量池的符号引用解析为直接引用,这一步可以和初始化互换顺序
初始化- 静态代码块、static 修饰的变量赋值、static final 修饰的引用类型变量赋值,会被合并成一个 cinit 方法,在初始化时被调用
- static final 修饰的基本类型变量赋值,在链接阶段就完成
- 初始化也是懒惰执行
类加载器
JDK 8 的类加载器
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
| Bootstrap ClassLoader 启动类加载器 | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader 扩展类加载器 | JAVA_HOME/jre/lib/ext | 上级为 Bootstrap,显示为 null |
| Application ClassLoader 应用类加载器 | classpath | 上级为 Extension |
| 自定义类加载器 | 自定义 | 上级为 Application |
双亲委派模型
含义:优先委派上级类加载器进行加载,如果上级类加载器
- 能找到这个类,由上级加载,加载后该类对下级类加载器可见
- 找不到这个类,则下级类加载器才有资格加载
目的:
- 让上级类加载器的类对下级共享,即能让你的类依赖到 JDK 的核心类
- 让类的加载有优先次序,保证核心类优先加载
四种引用类型
分别是:强引用、软引用、弱引用、虚引用
强引用
- 普通变量赋值就是强引用,如 ==A a = new A();==
- 通过 GC Root 的引用链,如果强引用找不到该对象,该对象才能被回收。

软引用 SoftReference
- 例如:==SoftReference a = new SoftReference(new A());==
- 如果仅有软引用引用该对象时,首次垃圾回收不会回收该对象,如果内存仍然不足,再次垃圾回收才会回收
- 软引用的自身需要配合引用队列来释放
- 典型例子是反射数据

弱引用 WeakReference
- 例如:==WeakReference a = new WeakReference(new A());==
- 如果仅有弱引用引用该对象时,发生垃圾回收就会释放对象
- 弱引用自身需要配合引用队列来释放
- 典型例子是 ThreadLocalMap 中的 Entry 对象
虚引用 PhantomReference
- 例如:==PhantomReference a = new PhantomReference(new A(), referenceQueue);==
- 必须配合引用队列一起使用,当虚引用所引用的对象被回收时,由 Reference Handler 线程将虚引用对象入队,这样就可以知道哪些对象来回收,从而对他们关联的资源做进一步处理
- 典型例子就是 Cleaner 释放 DirectByteBuffer 关联的直接内存
finalize 关键字的理解
finalize
它是 Object 中的一个方法,如果子类重写它,垃圾回收时此方法会被调用,可以在其中进行资源 释放和清理工作。 但是,将资源释放和清理放在 finalize 方法中非常不好,非常影响性能,严重时甚至会引起 OOM,从 Java9 开始就被标注为 ==@Deprecated==,不建议被使用了
finalize 原理
对 finalize 方法进行处理的核心逻辑位于 ==java.lang.ref.Finalizer== 类中,它包含了名为 ==unfinalized== 的静态变量(双向链表结构),Finalizer 也可被视为另一种引用对象(地位与软、弱、虚相当,只 是不对外,无法直接使用)
当重写了 finalize 方法的对象,在构造方法调用之时,JVM 都会将其包装成一个 ==Finalizer== 对象,并 加入 ==unfinalized 链表==中
Finalizer 类中还有另一个重要的静态变量,即 ==ReferenceQueue== 引用队列,刚开始它是空的。当 狗对象可以被当作垃圾回收时,就会把这些狗对象对应的 Finalizer 对象加入此引用队列
但此时 Dog 对象还没法被立刻回收,因为 unfinalized -> Finalizer 这一引用链还在引用它嘛,为 的是【先别着急回收啊,等我调完 finalize 方法,再回收】
==FinalizerThread== 线程会从 ReferenceQueue 中逐一取出每个 Finalizer 对象,把它们从链表断开并 真正调用 finallize 方法
由于整个 Finalizer 对象已经从 unfinalized 链表中断开,这样没谁能引用到它和狗对象,所以下次 gc 时就被回收了
finalize 缺点
- 无法保证资源释放:FinalizerThread 是守护线程,代码很有可能没来得及执行完,线程就结束了
- 无法判断是否发生错误:执行 finalize 方法时,会吞掉任意异常(Throwable)
- 内存释放不及时:重写了 finalize 方法的对象在第一次被 gc 时,并不能及时释放它占用的内存,
- 因为要等着 FinalizerThread 调用完 finalize,把它从 unfinalized 队列移除后,第二次 gc 时才能真正释放内存
- 有的文章提到【Finalizer 线程会和我们的主线程进行竞争,不过由于它的优先级较低,获取到的 CPU 时间较少,因此它永远也赶不上主线程的步伐】这个显然是错误的,FinalizerThread 的优先 级较普通线程更高,原因应该是 finalize 串行执行慢等原因综合导致
如何排查频繁 Full GC?
- 代码层面:System.gc()调用,一般不会调用
- 新生代空间太小,youngGC 频繁,存活对象太多,但是 survivor 放不下,导致对象过早进入老年代
- 老年代空间不足,大对象直接进入
- 元空间内存不足:大量代理类,类加载器是活的,元空间类的元数据也是活的。
- ==top -c==: 找到 cpu 占用很高的进程 ID:==PID==
- jstat -gc pid 查看 GC 情况
- jmap -dump:format=b,file=temp.dump pid dump 文件
- MAT 分析是否有内存泄漏,看是哪个大对象。MAT 查看类的 Histogram 直方图。
开启 GC log
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintTenuringDistribution
-Xloggc:/some-path/gc-$(date +%Y%m%d-%H%M%S).log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=10M
如何排查 CPU 占用过高的问题?
- ==top -c==: 找到 cpu 占用很高的进程 ID:==PID==
- ==top -H -p PID==:查看最占用 CPU 的线程 ID
- ==printf "0x%x\n" 74318==:得到对应 16 进制线程 ID
- ==jstack 进程 ID | grep -A 20 十六进制线程 ID==:打印对应进程的堆栈信息
- 找到对应线程的 JAVA 代码行,分析问题
一般原因可能是死循环,或者频繁 GC
如何排查内存占用很高的问题?
==top -c==:找到 mem 占用很高的进程 ID
==top -H -p 111111==:找到占用很高内存的线程
如果是线上环境,注意 dump 之前必须先将流量切走,否则大内存 dump 是直接卡死服务。
# dump当前快照 jmap -dump:live,format=b,file=dump.hprof <pid># 触发full gc,然后再dump一次 jmap -dump:live,format=b,file=dump_gc.hprof <pid>dump:live 的作用是会触发 Full GC,然后再 dump 数据,用作 gc 前后的数据做对比。
通过 MAT (Memory Analyzer Tools) 分析 dump 文件
JVM 调优思路
优化指标:吞吐量、停顿时间和垃圾回收频率。
基于这些我们可能需要调整:
==内存区域大小以及相关策略==:堆内存大小、新生代大小、老年代大小、Survivor 大小、晋升阈值等等
- -Xmx
- -Xms
- -Xmn
- -XX:SurvivorRatio
按经验来说:IO 密集型的可以稍微把年轻代增大些,内存计算密集型的稍微把老年代增大些。
==垃圾回收器==:选择合适的垃圾回收器和垃圾回收期的各种调优参数
- -XX:UseG1GC
- -XX:MaxGCPauseMillis
- -XX:InitialingHeapOccupancyPercent
大多数情况下,一般是遇到问题之后才进行调优的。
JIT 即时编译器
两种技术:方法内联和逃逸分析(==锁消除==、==栈上分配==、==标量替换==)。
方法内联:把目标方法的代码复制到调用的方法中,避免发生真实的方法调用。因为每次方法调用都会生成栈帧,压栈、出栈、记录方法调用位置等等会带来一定的性能损耗,所以方法内联可以提高一定的性能。逃逸分析:判断一个对象是否被外部方法引用或者外部线程访问的分析技术,如果没有被引用就可以进行优化,例如:- ==锁消除(同步忽略)==:锁的对象只在方法内被调用,不会被别的地方调用,那么就一定是线程安全的,可以把锁的代码忽略掉。
- ==栈上分配==:该对象只会在方法内部被调用,直接把对象分配在栈中而不是堆中,因为堆中对象需要通过垃圾回收器进行回收,需要损耗一定性能
- ==标量替换==:当程序执行的时候可以不创建对象,而是直接创建这个对象的成员变量来代替。对象拆分后,可以分配对象的成员变量在栈或寄存器上,原本的对象就不需要分配空间了。